Redis的RDB与AOF
Redis的RDB与AOF
对于Redis而言,它的数据都是存在内存当中的。如果我们想要将数据永久性的存下来,或者下次重启Server后,想要以前的数据依然在,那么我们就需要将内存中的数据持久化到硬盘中。而Redis对于这样的需求,为我们提供了两套服务,分别是RDB与AOF。
前言
在讲解什么是RDB,什么是AOF之前,我们要先明白对于任何一个内存型的DB而言,如果我们想要持久化数据,我们应该怎么做?但是,本节主讲Redis。因此在这里,我们依然以Redis举例。
假如我们有一个Redis,这个Redis运行了很久,在内存中产生了很多的数据。此时我们需要将这些内存中的数据持久化到硬盘上,供后续的其他操作使用。在这样的情况下,我们有两个操作:
- 阻塞掉前端所有的
client端的操作。然后将这些数据缓缓的写到磁盘当中。只有将全部的数据写入完毕之后,此时再放行client端的操作。 - 通过新启动一个子进程的方式,通过子进程的方式,将内存中的数据缓缓的写入到磁盘当中。
Redis的工作线程依然处理客户端的请求。
这两种方式各自有各自的特点。接下来,我们开始一一讨论。
第一种方式
首先,我们要明确一点,对于整个系统而言,最大的瓶颈是IO操作,至于为什么是IO操作,详情可以参考百度。那么如果采用的是当前的方式,就会出现如果当前内存的数据量特别大的时候,此时Redis将内存中的数据写入硬盘的时间就会特别的长,从而就会造成Redis长时间处于一种服务不可用的状态。对于这样的情况,虽然可以保证我们缓存到硬盘的内容是100%准确的,但是我想没有几个公司会同意这样的解决方案的。这也是为什么很多公司将Redis的SAVE命令给禁用的原因。
这里说明下,Redis是支持第一种方案的。对应的的命令是SAVE。
第二种方式
既然第一种方式公司不让用,那么我们来看下第二种方案。对于第二种方案而言,你可能会想,这样的方式虽然保证了服务的可用性,但是如果我在缓存的过程中,如果我将对应的key的值给改了,或者将这个Key对应的值给删除了,怎么办?这样就会造成数据不一致的问题。如果想要数据一致的话,还是需要STW的,事实上真的是这样吗?我们做一个例子:
进程间资源隔离的例子
首先,我们新开一个session,然后执行pstree命令,如图所示:
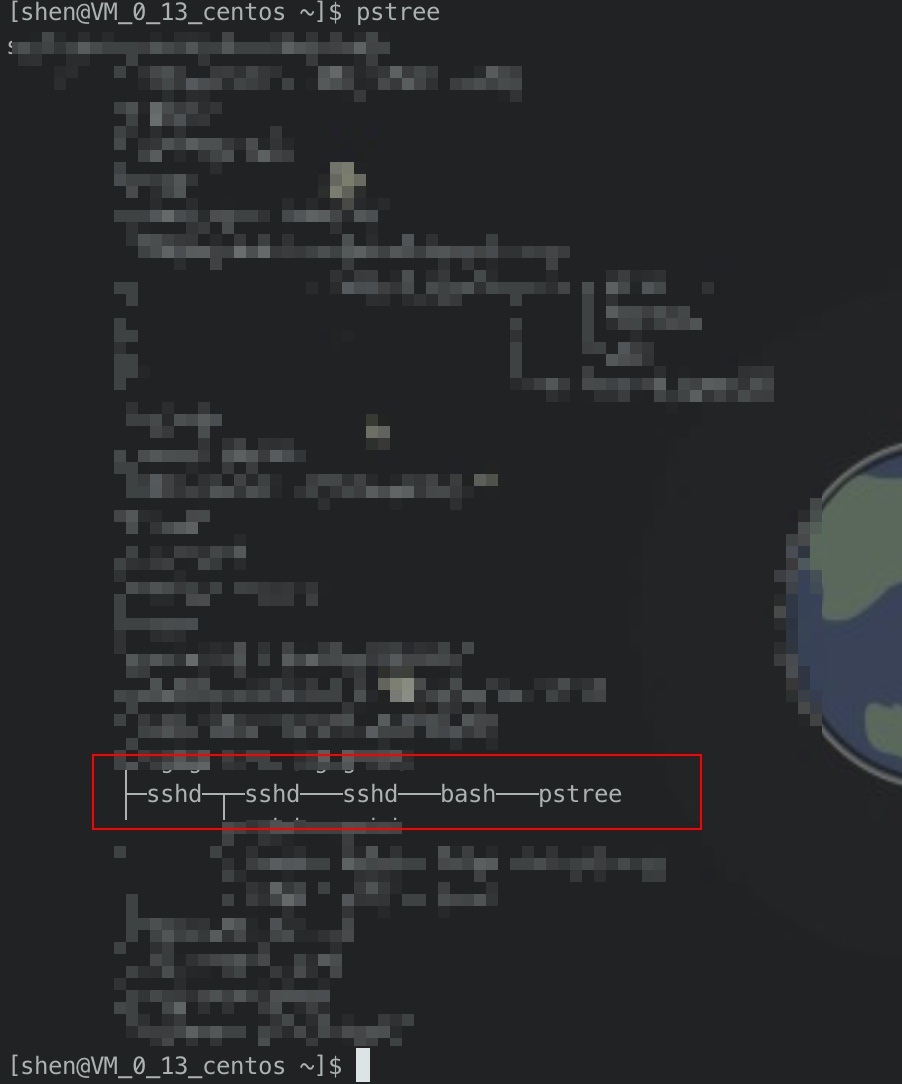
我们发现,目前我们处在bash下,执行的pstree命令。此时我们设定一个变量b,值为10。
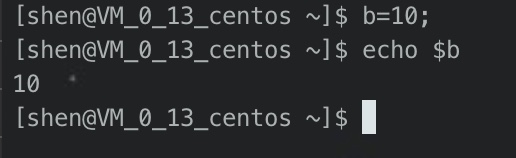
通过上图所示,我们已经在当前的session中,设置了一个变量b,值为10,并且已经能够成功的取出。
接下来,我们创建一个子进程,使用/bin/bash命令。然后我们再看一下pstree。
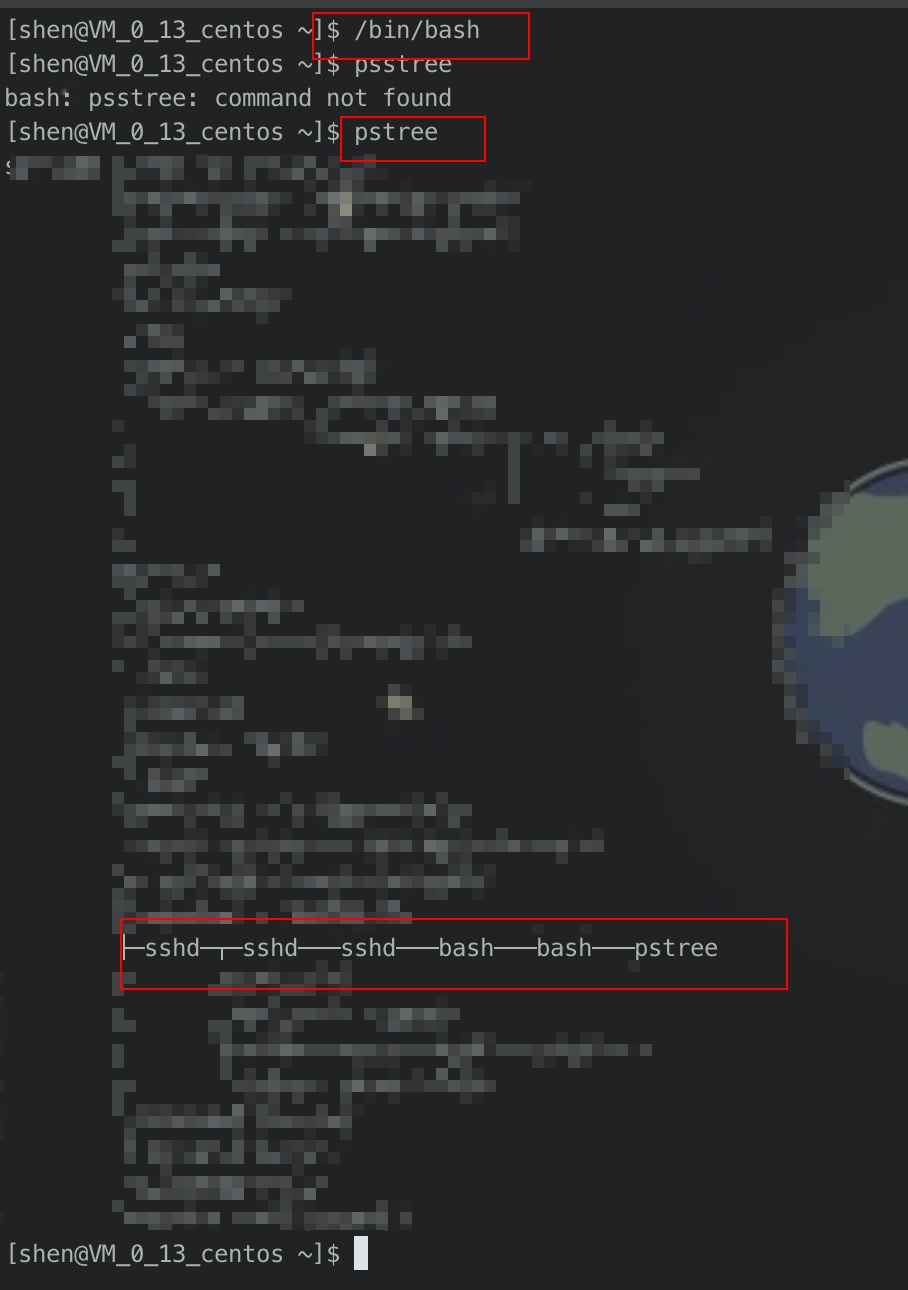
此时我们发现,和之前的pstree进行比较,我们目前是在bash->bash下执行的pstree。此时我们在获取之前创建的变量b.
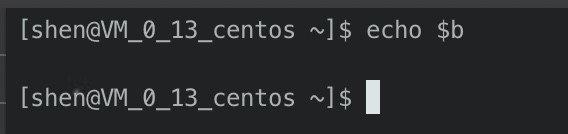
此时我们发现,我们并没有得到b的值,这是为什么呢?
这是因为在Linux系统中,进行之间的资源是相互隔离的。如果我们想要让b在两个session之前共享,最简单的办法就是使用export命令,然后在子进程就能够获取的到了。
OK,通过上面的例子,我们知道了线程间的资源隔离问题。那么对应到Redis而言,又是怎么做的呢?在这里,我们还需要另外一个知识,虚拟地址映射。
对于Redis而言,我们每次存储的一个key-value的键值对,都是存在真实的物理内存中的,而这些地址,在Redis中存在着一份映射关系。我们通过下面的图,举个栗子,(这里说明下,下图的内容仅仅只是为了理解,而不是Redis底层的真正实现) 。
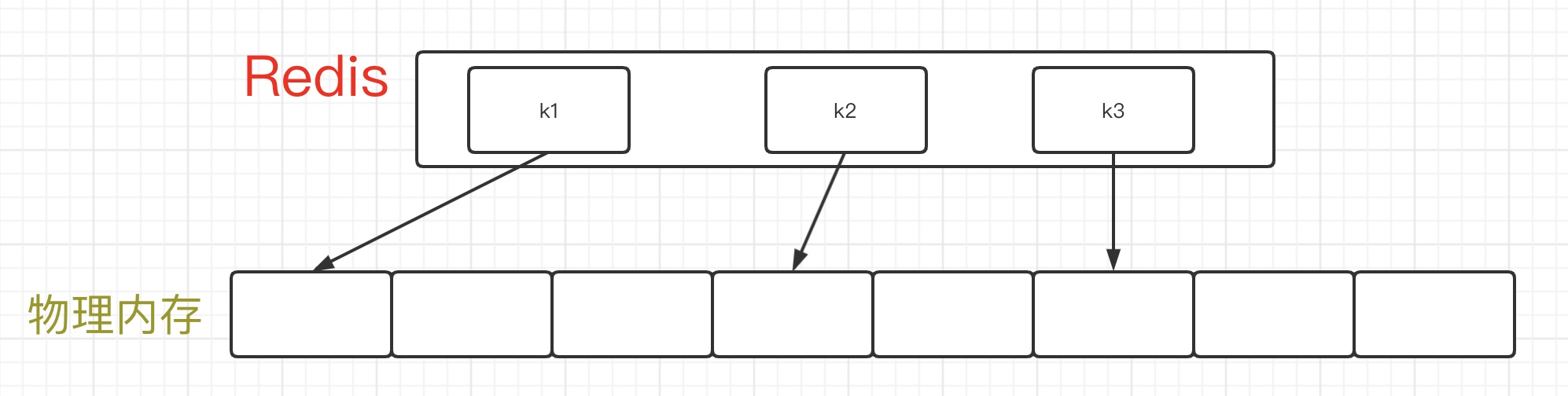
此时Redis要进行数据持久化的时候,是通过调用系统的fork命令来创建一个子进程的。而子进程依然会保留着这份映射关系,并且fork的时间特别的快,不会阻塞到client端的请求。也就是会变成下图的样子:
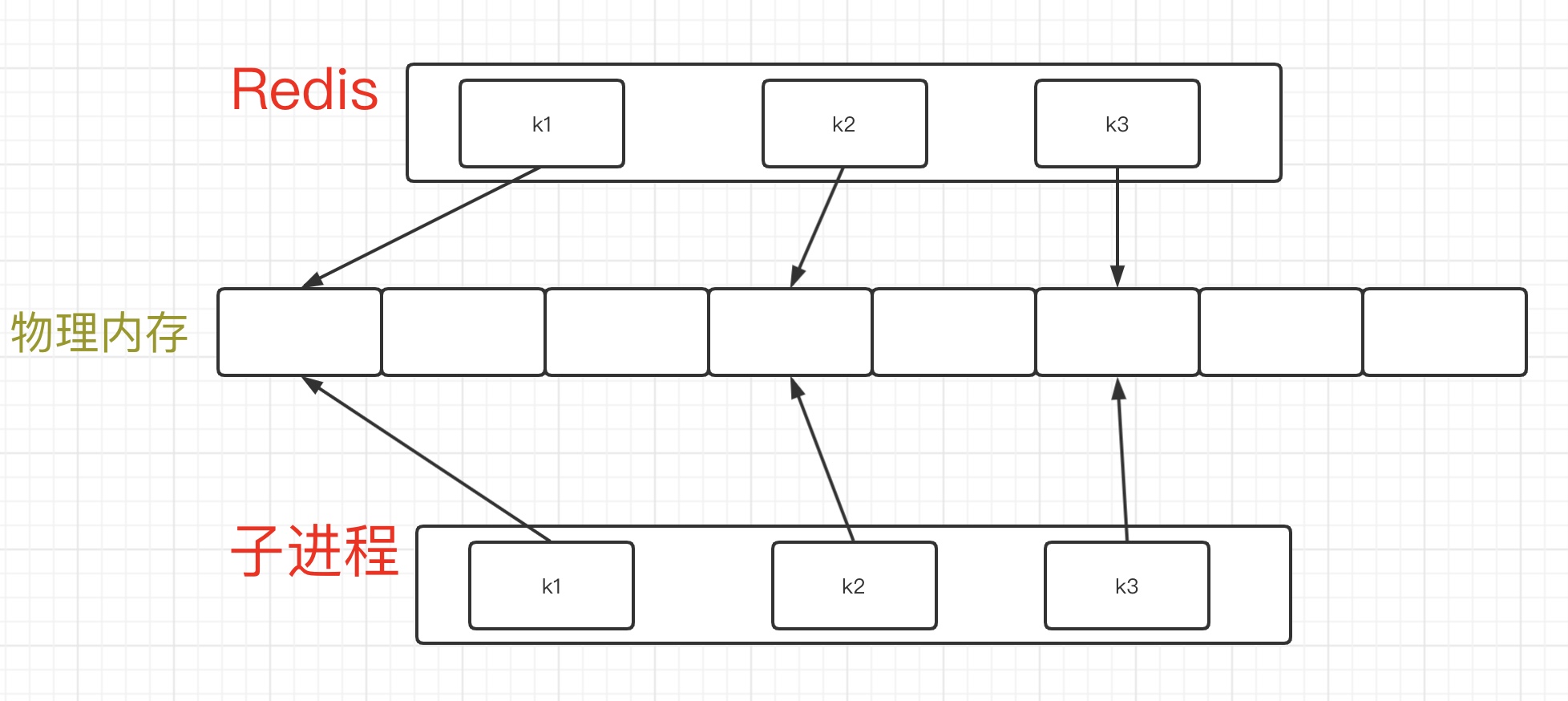
如果我们的Redis的工作进程,需要对k1进行修改,此时Redis会采用copy-on-write的方式,也就是说,他不会去改物理内存中1号位置的值,而是将新的内容写入到2号位置,改变指针即可。这样对于子进程而言,我拿到的依然是修改前的值。
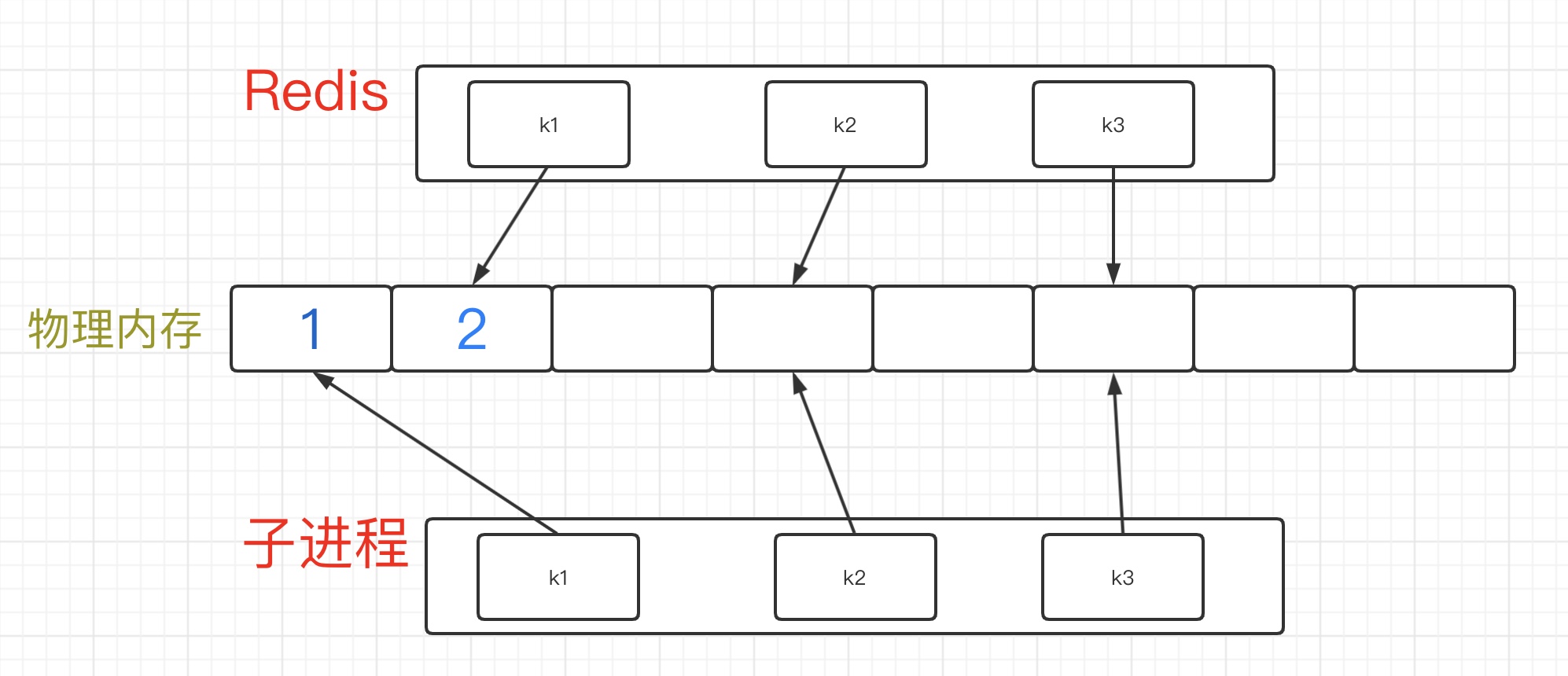
对于这样的操作方式,Redis也为我们提供了指令BGSAVE。我们可以通过调用BGSAVE,来实现将数据异步的存储到硬盘中。
什么是RDB
通过上面的解释,我们知道了Redis是如何将数据存储到硬盘中的。而RDB就是采用的上述描述的第二种方式。因此,对于RDB而言,我们存储的数据并不是实时的。例如我们在8点钟执行了BGSAVE,或者系统自动触发。在9点钟的时候,完成了数据的持久化,根据上面的讲解,我们知道对于8点到9点之间的数据变更,并没有存储到RDB文件当中,并且BGSAVE操作,每次存储数据都是全量存储的。所以这样的存储方式会产生数据遗漏的问题。
RDB的配置
对于RDB的生成,我们可以采用前面介绍的命令BGSAVE,或者也可以采用配置文件的方式进行配置,在这里,我主要讲解下配置文件的配置方式:
save 900 1
save 300 10
save 60 10000对于Redis而言,默认已经开启了RDB持久化,同时,给出的默认设置是:
1.如果60s内的写操作大于10000次,则自动开启BGSAVE
2.如果300s内的写操作大于10次,则自动开启BGSAVE
3.如果900s内的写操作大于1次,则自动开启BGSAVE以上的三个条件,只要满足其中的一个,就会触发BGSAVE。
这里要注意下,在配置文件中,虽然我们是通过save指令来指定RDB的触发机制,但是在Redis中,触发的不是save指令,而是BGSAVE指令。
同时,我们可以通过dbfilename与dir分别指定RDB文件的名称和存储的路径。
什么是AOF
上面我们介绍了RDB的一个执行的原理和过程,但是我们发现一个问题,它并不能实时的持久化最新的数据,基于这个问题,Redis给我们提供了另外一种存储方式AOF。
对于AOF而言,他存储的并不是内存中的数据,而是用户的一条条指令。Redis会将用户的每一条指令,通过追加到文件的方式,写入到一个日志文件中,这个就是AOF。
在这里,我们要注意下,对于AOF,Redis默认并没有自动开启,需要我们手动的在redis.conf配置文件中开启。开启的命令就是将appendonly从no改成yes。同时可以通过appendfilename指定AOF文件的名称。
在这里,我们要注意下,对于AOF的写入存在着以下三个时机:
no:指的是当每次内核中的缓冲buffer满了以后,会自动的往AOF文件中flush一次。- 优点:降低了
IO的频率 - 缺点:容易丢失一个
buffer的数据
- 优点:降低了
always:指的是当每次发生一次写操作,都会立即往AOF文件中flush一次。- 优点:最大可能的保证了数据的准确性
- 确定:提高了
IO的频率
everysec:每秒中调用一次flush,是上面两个方案的折中。
在Redis的配置文件中,默认采用的是第3种方案,可以通过修改redis.conf中的appendfsync对应的value来起到改变策略的目的。
同样的,对于AOF的操作,我们也可以采用BGREWRITEAOF命令来手动的发起。
AOF策略的优化
Redis 4.0之前的版本
在Redis4.0之前的版本中,Redis对于AOF的操作的优化主要是在rewrite中进行的。
在这里我们举个栗子:假如我们有一个新的Redis实例,里面的数据为空,此时我们有个程序,不停的对同一个key进行incr。在执行完100W次以后,此时我们的AOF文件会变得很大。因为AOF文件,相当于要记录下100W操作的每次的完整的命令。在这里,我们以k1为key做演示,仅INCR一次,我们看下AOF的文件内容:
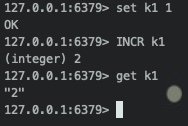
此时我们通过客户端,执行set incr get 命令后,通过配置文件,找到对应的AOF文件,然后打开(我已将appendfsync改成了always,方便看到效果 ):
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$1
1
*2
$4
incr
$2
k1此时我们发现,AOF的文件内容居然是这样的。接下来,我们解读下当前命令:
*2:代表的是接下来,我要读取两个值,分别是SELECT和0。代表我们读取第0号数据库。$6、$1代表的是指令的长度,并不在*2的读取范围内。- 接下来,所有的命令依次类推即可。
上面的内容还仅仅只是incr依次的结果,如果我们incr多次呢?这个AOF的文件会变得特别的大,将来Server启动,load数据的时候,会变得的慢。试下一下,如果我执行了100W次的incr k1,其实下次程序启动,直接设置set k1 = 10100000即可。
对了,在这里要说明下,在程序启动的时候,如果没有开启AOF,此时程序会以RDB的文件内容为准,如果开启了AOF,则会以AOF文件中的内容为准。
基于上面的原因, Redis在文件达到指定大小和指定增加百分比的时候,对AOF文件会进行rewrite操作。其中可以通过Redis.conf的auto-aof-rewrite-min-size来指定重写文件的最小值,auto-aof-rewrite-percentage来指定当文件达到多大的百分比时进行rewrite。在Redis中,设置的默认大小分别为64MB和100。
rewrite操作,会对文件中的命令进行整合,从而起到消除文件大小的作用,但是一旦Redis发生了rewrite操作之后,此时仅仅保留的就是最终的信息,对于数据的一个变迁的过程,无法再看见了。同时,对于文件的整合,是非常消耗CPU性能的。
接着上面的命令,我们执行下BGREWRITEAOF指令,再来看下AOF文件的内容:
*2
$6
SELECT
$1
0
*3
$3
SET
$2
k1
$1
2此时我们发现,在AOF文件中,已经将k1直接设置成了2。删去了k1的数据变迁过程。
Redis 4.0及之后的版本
在Redis 4.0之前的版本,对于RDB和AOF可以同时开启,但是Redis在启动的时候,仅仅只会使用其中的一个。但是在Redis4.0之后的版本中,可以通过redis.conf中的aof-use-rdb-preamble来指定是否将RDB与AOF混合起来一起使用。在Redis4.0之后的版本中,Redis已经默认开启了混合使用的策略。
那么什么是混合使用呢?混合使用其实就是在rewrite的时候,对于rewrite之前的数据,采用RDB的方式存到文件中,便于后续程序在启动的过程中能够快读的laod数据,而对于rewrite期间,redis产生的写操作,则通过AOF的方式,追加到文件的末尾。大大的提高了程序的效率。
接下来,还是上面的例子,我们将redis清空,删除所有的持久化文件,将aof-use-rdb-preamble改成yes。再执行上线的操作,查看AOF文件:
set k1 1
incr k1
get k1
BGREWRITEAOF
set k2 10
get k2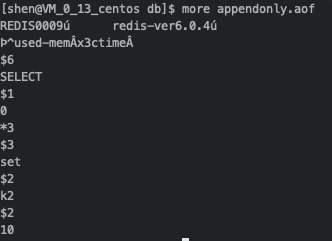
我们发现,文件的开头已经是一堆乱码了。但是在程序只有,依然是我们的set k2 10这个命令。同时我们发现,在AOF的文件的开头,是REDIS。这个算是RDB文件开头的一个标识。代表的是RDB文件的内容。
总结
在这篇文件中,我们学习了Redis的RDB与AOF的存储原理和存储过程。同时对于配置文件中的配置,也起到了说明的作用。供自己以后的参看。
转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以邮件至 gouqiangshen@126.com
文章标题:Redis的RDB与AOF
文章字数:3.3k
本文作者:BiggerShen
发布时间:2020-06-08, 16:47:08
最后更新:2024-01-16, 03:51:15
原始链接:https://shengouqiang.cn/Redis/RedisPersistence/版权声明: 转载请保留原文链接及作者。

